AIテスト -オーバーサンプリング手法-
- AIソリューション
- ソフトウェアテスト・品質保証


Introduction
AIタスクにおいて、データセットの質・量がAIの推論精度を決めるうえで重要なポイントの1つになりますが、データセットが不均衡であることは往々にして存在します。
特に分類問題において、データセットが不均衡だと大きな問題になることがあります。
※分類問題とは、例えば診断予測で陽性か陰性かのような2値分類の問題のことを指します。


目次
不均衡なデータセットだとなぜ問題か?

例えば、2値分類のAIタスクの場合、データセットのクラスは陽性か、陰性かの2種類となり、もし陽性のデータセットが極端に少ない場合、例えば 陽性が全体の10%、陰性が90%を占めるとします。
AIの予測モデルを作成した場合、常に陰性と予測したとしても、正解率が90%となり、そのような予測モデルが作成されるかも知れません。
上記は極端な例ですが、片方のクラスが極端に少ない不均衡なデータセットの場合、モデルが適切に特徴・パターンを学習するのが困難となり、少数派クラスの予測精度が悪化する可能性があります。
では、このようなデータ不均衡問題をどのように解消すれば良いでしょうか?
1つの方法として、オーバーサンプリング(データセットをかさ増しする)手法のなかに、SMOTEと呼ばれる手法があります。
これは少数派クラスのデータを増やすことで、偏りを減らして、より均衡なデータセットを作成する方法となります。
SMOTE手法の概要
SMOTE(Synthetic Minority Over-sampling Technique)手法とは不均衡データセットのクラス間のサンプル数の差を解消するための一般的なオーバーサンプリング手法の1つです。
SMOTEの基本的なアイデアは、少数派クラスにおいて、近接した既存サンプルデータ間に新しいサンプルを内挿して生成する事により、不均衡状態を解消するものです。
※内挿とは、2つの点の内側に点を挿入する事を指します。
アルゴリズム概要:
1. 少数派クラスから、ランダムに1つのデータ点を抽出する
2. 抽出したサンプルに対して、最近傍のデータからランダムにサンプルデータを選択する
3. この2つのサンプル間に新しいサンプル点を挿入して生成する
4. 上記を繰り返す
これは単に既存の少数派クラスのデータをコピーするのではなく、新しいサンプルを生成する方法です。
イメージ図
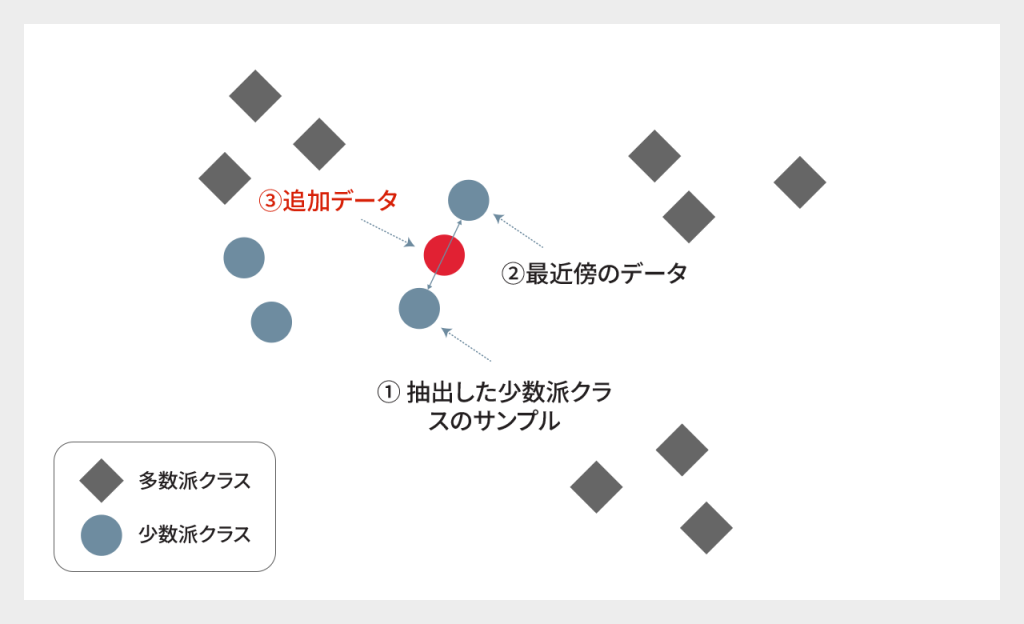
※最近傍の探索は、K近傍法などを用います。
関連サービスについて

SMOTE手法の派生
SMOTE手法には多数の派生アルゴリズムがあり、いくつかを紹介します。
・ADASYN (Adaptive Synthetic Sampling)
クラス境界付近にデータを増やす手法。
少数派クラスのデータ周辺に多数派クラスがどの程度存在するかの情報を加味して、サンプルを生成し、付近に多数派クラスが多いほど新しいデータを生成します。
・Borderline SMOTE
上記のADASYNと似ており、クラス境界付近にデータを増やす方法ですが、付近のデータのクラスの分布割合のバランスを考えて、少な過ぎず、多過ぎずの領域に増やす方法です。
・SMOTE-NC(Categorical SMOTE)
通常のSMOTEでは、数値データの補完に基づいて新しいデータを生成しますが、カテゴリカルデータ(非数値)を含むデータセットにも対応しています。
例えば、地域、製品カテゴリなどカテゴリカルデータを含む場合でも、SMOTE-NCはオーバーサンプリングします。
・SMOTE Regression
今までは、分類問題に対してのSMOTE手法を紹介してきましたが、回帰問題(連続値の予測)の場合は、分類問題用のSMOTEは使えません。
代わりに回帰用の SMOTE Regressionと呼ばれる手法があり、それを利用する必要があります。
回帰の場合は出力が連続値となりますが、連続値の分布において頻度が少ないデータをオーバーサンプリングする手法となります。
以上、いくつかのSMOTEを紹介してきましたが、SMOTE関数については、例えば Pythonのライブラリとして提供されているものがあるため、実際に調べて使ってみると良いでしょう。
アンダーサンプリング
紹介したSMOTE手法はオーバーサンプリングの1手法でしたが、アンダーサンプリングと呼ばれる多数派クラスのデータを減らすまたは、少数派のデータ数に合わせることで、不均衡状態を解消する手法があり、多数派クラスをランダムに削除するかより洗練された多数派クラスを削除する方法などがあります。
ただし、アンダーサンプリングに関しては多数派のデータを削除しているため、重要なデータまでもが削除されてしまい、元の多数派のデータに対してバイアス(偏り)が生じる可能が出てきます。例えば世帯情報から住んでいるエリアを予測するAIを作成しているとします。この場合多数派のデータをアンダーサンプリングによりランダムで削除されていた際に、削除したデータに高年収の世帯が多く含まれていると、元の多数派のデータの情報に関してデータ内の年収情報にずれ、すなわち偏りが生じる可能性が発生します。そのため、アンダーサンプリングに加えて、データを分割しそれぞれをAIによる学習モデルを複数作成後にモデルを統合するバギングと呼ばれる手法を組み合わせた方法などが提案されています。
SMOTEの利用シーン

データセットが不均衡な場合に、少数派クラスをオーバーサンプリングにより解消する手段として SMOTEを紹介しました。
一方で、例えば画像認識における画像データの場合は、画像の幾何変換(移動、リサイズ、回転等)により同じクラスのデータを容易に増やすことが出来るため、SMOTEを使う必要がありません。
しかし、容易にデータを増やすことが出来ない場合(例:構造化されたテーブルデータ)はSMOTEが有効な手段の1つとなります。
また、SMOTE手法は、モデル学習段階のデータセットの均衡化以外に、学習済みモデルをテスト・評価する際の未知のデータを作成する手段としても有効です。
これにより学習に使ったデータ以外の未知データに対する汎化性能(安定性)を評価する事が出来ます。
一方で、SMOTE手法の限界として、新しいサンプルデータの作成が必ずしも現実のデータ分布を反映しない可能性もある事に留意する必要があります。
AIシステムの品質保証

本資料は、AIシステムの品質保証をテーマに、 SHIFTで実施しているノウハウを紹介しながら具体的な手法や進め方などを説明しています。
AIシステムの安全性と信頼性を確保することで、ユーザーに安心感を提供し、その結果、より広範囲での利用を促進いただけます。品質が確保されたAIシステムは、予測精度が高まり、ビジネスの意思決定や社会問題の解決に大きく貢献します。ぜひご覧ください。
本資料は、AIシステムの品質保証をテーマに、 SHIFTで実施しているノウハウを紹介しながら具体的な手法や進め方などを説明しています。
AIシステムの安全性と信頼性を確保することで、ユーザーに安心感を提供し、その結果、より広範囲での利用を促進いただけます。品質が確保されたAIシステムは、予測精度が高まり、ビジネスの意思決定や社会問題の解決に大きく貢献します。ぜひご覧ください。
まとめ
不均衡データセットを解消する方法の1つとして、オーバーサンプリング手法の1つのSMOTE手法を紹介してきました。
これは、少数派クラスのデータを近傍のデータを用いて追加することで、不均衡状態を解消する方法でした。
SMOTE手法は、モデル学習段階のデータセットの均衡化以外に、学習済みモデルをテスト・評価する際の未知のデータを作成する手段としても有効です。
これにより学習に使ったデータ以外の未知データに対する汎化性能(安定性)を評価する事が出来ます。
一方で、SMOTE手法の限界として、新しいサンプルデータの作成が必ずしも現実のデータ分布を反映しない可能性もある事に留意する必要があります。
従って、オーバーサンプリング、アンダーサンプリング、その他のテスト手法などさまざまな手法を検討して、より適切な対応をとることが肝要となります。
>>SHIFTのAI特化型品質保証サービスページへ
>>お問い合わせページへ
>>料金についてページへ
この記事を書いた人
ご支援業種
- 製造、金融(銀行・証券・保険・決済)、情報・通信・メディア、流通・EC・運輸、ゲーム・エンターテイメント
など多数